October 2025
From connectome-constrained dynamics and projection-specific population codes to human–ANN continual learning, and advances in hippocampal replay theory.
Between planning and map building: Prioritizing replay when future goals are uncertain
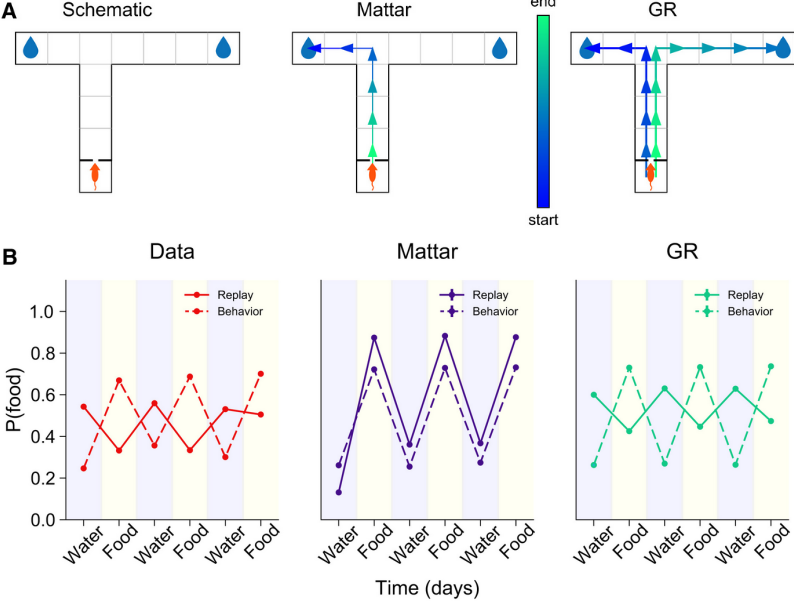
- Main Contribution: Extends reinforcement learning theory of hippocampal replay from planning (single goal) to map building (multiple potential goals) by introducing the geodesic representation (GR)—a stack of value functions encoding optimal routes to all candidate goals.
- Key Findings: Replay priority balances current versus future goals based on their expected relevance, determined by learned goal statistics. This reconciles seemingly contradictory findings:
- Paradoxical Replay (lagging behavior, favoring past goals) emerges when goal switching is slow and animals use recency-weighted estimates)
- Planning-like replay (leading behavior, favoring current goals) emerges when one goal predominates or switching dynamics are well-learned
- Predictions: Replay patterns should depend on goal volatility, task complexity, and animals’ understanding of goal dynamics—offering concrete experimental tests via manipulated goal-switching statistics.
Prediction of neural activity in connectome-constrained recurrent networks
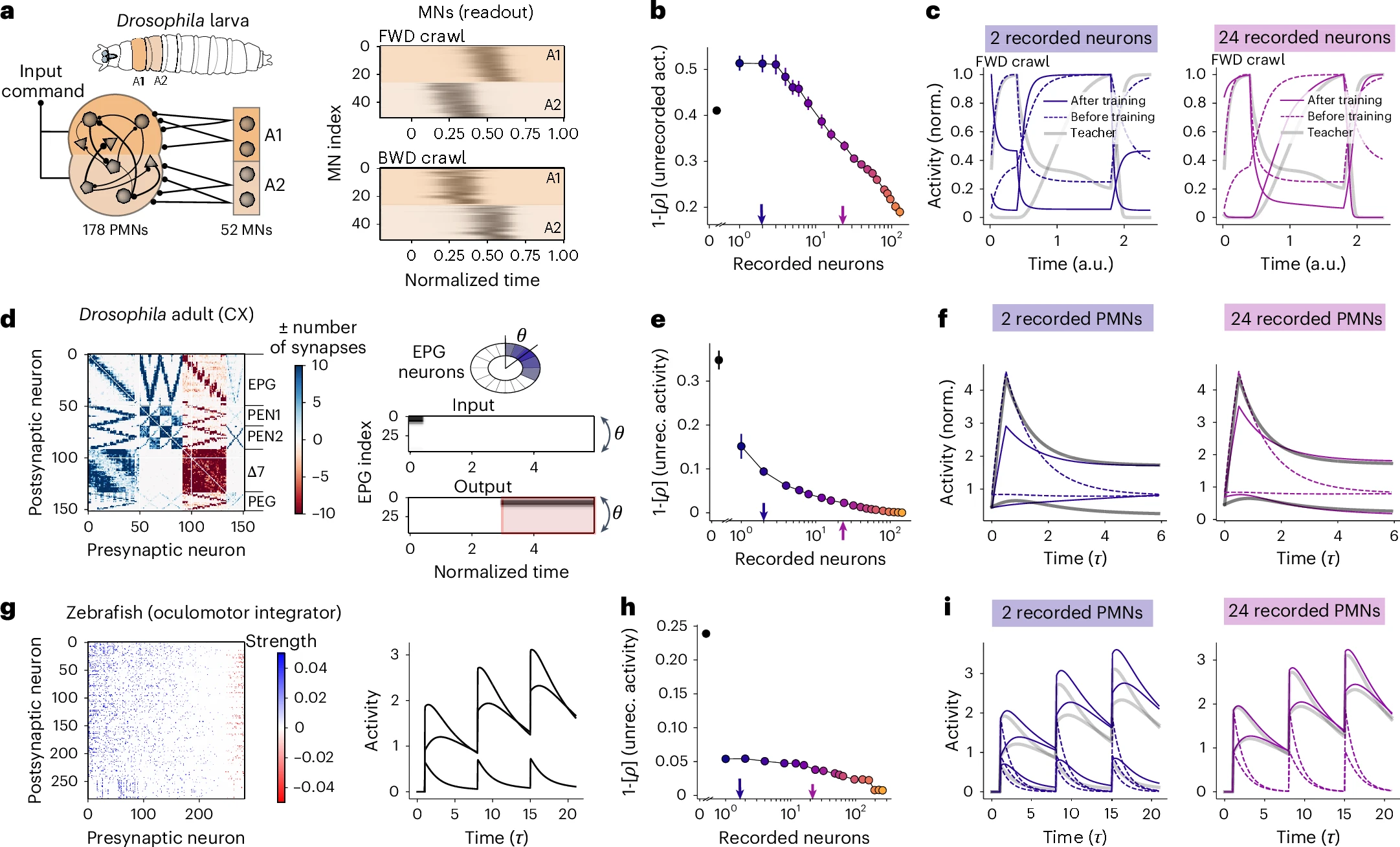
- Core idea: A “teacher–student” theory shows that knowing the exact synaptic weight matrix (connectome) is often insufficient to predict single-neuron dynamics because heterogeneous single-neuron parameters (gains, biases, etc.) create many degenerate solutions.
- Key result: Adding recordings from a small subset of neurons breaks this degeneracy; the number needed scales with the dynamical dimensionality, not neuron count.
- Implication: Connectomes best constrain function when paired with targeted activity data, and the framework can prioritize which neurons to record next.
Specialized structure of neural population codes in parietal cortex outputs
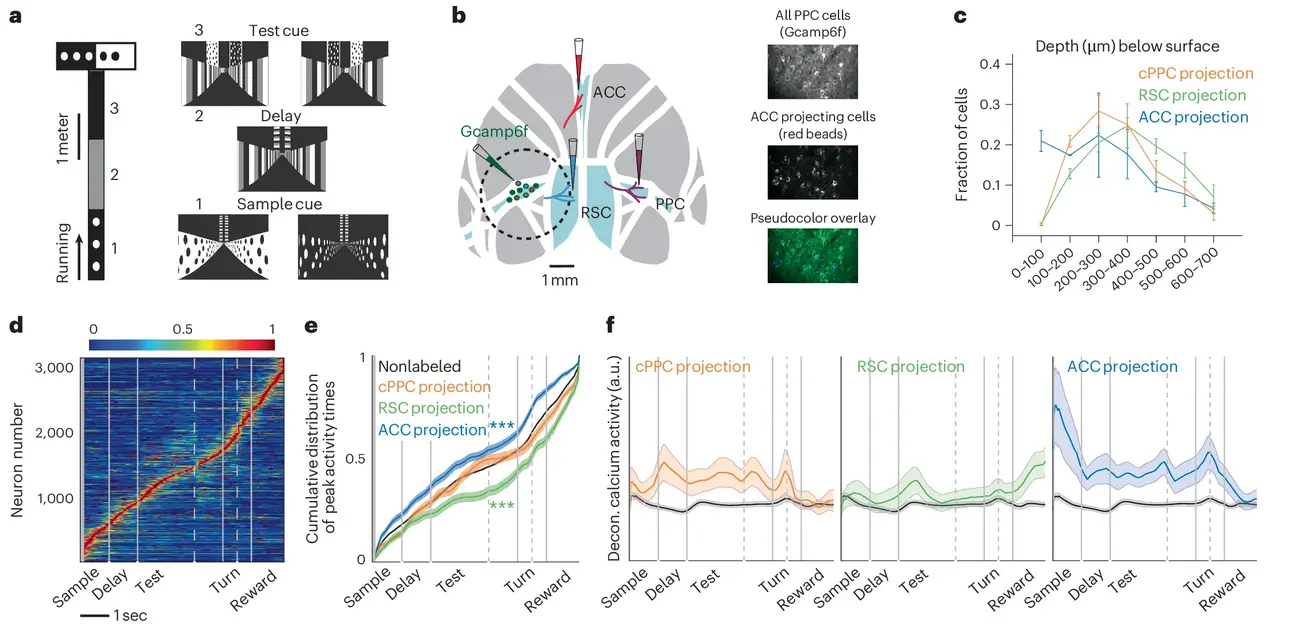
- Main contribution: Combined two-photon calcium imaging with retrograde labeling to identify neurons in mouse posterior parietal cortex projecting to the same target area (ACC, RSC, or contralateral PPC) during a virtual-reality delayed match-to-sample task, enabling analysis of projection-specific population codes.
- Key findings: Neurons projecting to the same target exhibit (1) elevated pairwise noise correlations compared to unlabeled neighbors; (2) a structured network of information-enhancing (IE) and information-limiting (IL) interactions organized as enriched within-pool IE and across-pool IL connections; (3) enhanced population information about the mouse’s choice that scales supra-linearly with population size via “structured interaction information” from triplet motifs. This specialized structure is absent in unlabeled populations and present only during correct, not incorrect, trials.
- Methodological advance: Developed nonparametric vine copula (NPvC) models to robustly estimate multivariate dependencies between neural activity, task variables, and movement variables, accounting for nonlinear relationships and enabling accurate quantification of single-neuron information, pairwise interaction information, and network-level information structures.
- Predictions: The network structure of correlations within projection pathways enhances information transmission to downstream targets and facilitates accurate decision-making. Structured interaction information contributes a substantial fraction (~5–15%) of total choice information in populations of 75+ cells, with contributions growing faster than independent information as population size increases.
Humans and neural networks show similar patterns of transfer and interference during continual learning
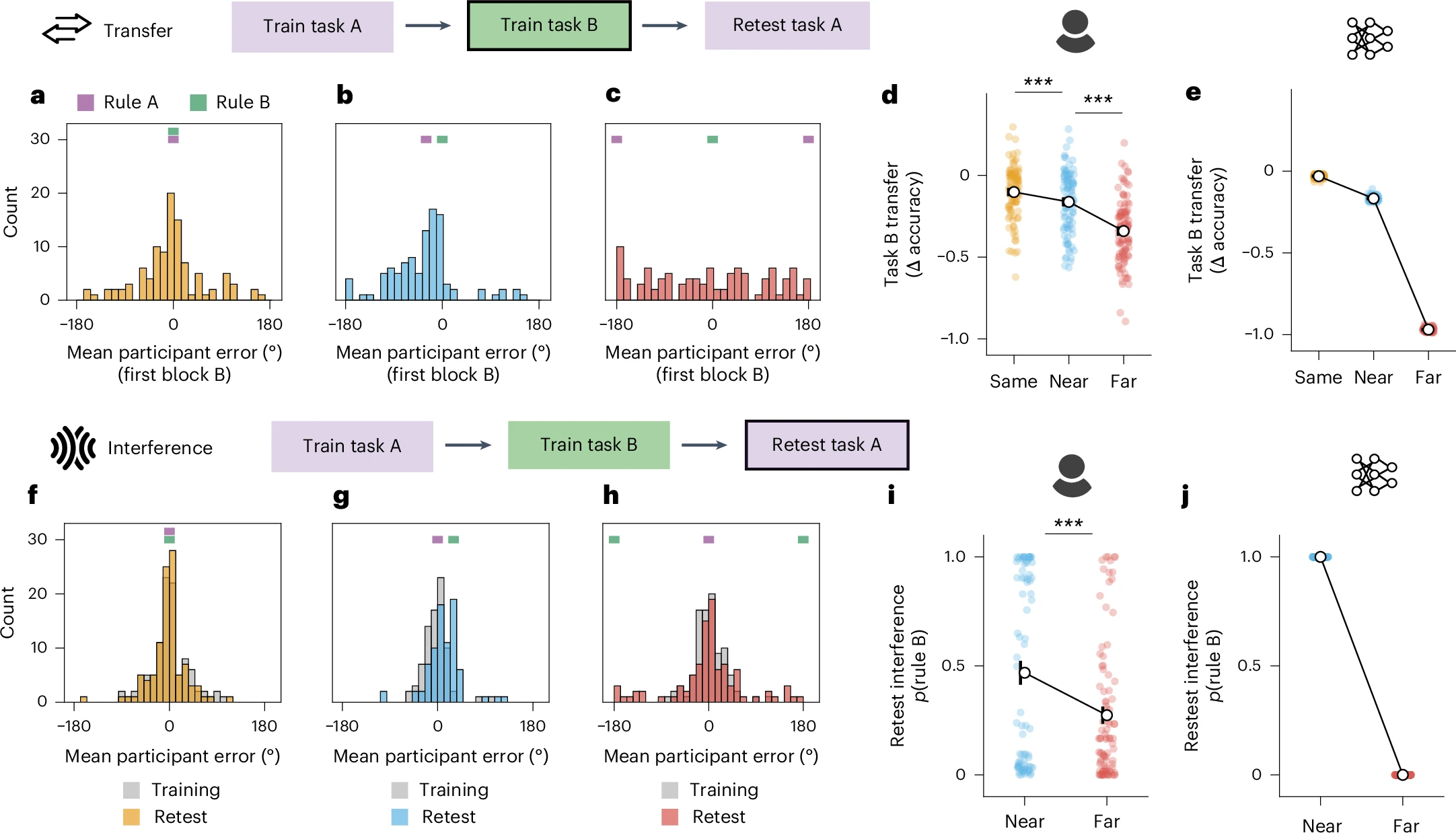
- Main contribution: Direct comparison of humans and twinned linear ANNs on sequential rule-learning tasks (A→B→retest A) with varying rule similarity (Same/Near/Far), revealing shared computational trade-offs between transfer and interference in continual learning.
- Key findings: (1) Both learners show greater transfer to task B when rules are similar, but at the cost of higher interference when retested on task A—driven by representational reuse in similar tasks versus orthogonal subspaces in dissimilar tasks. (2) Individual differences emerge in the Near condition: “lumpers” (47.5% of participants) show high transfer and interference via shared low-dimensional representations (mirrored by rich-regime ANNs), while “splitters” avoid interference but transfer poorly via high-dimensional, task-specific representations (mirrored by lazy-regime ANNs). (3) Lumpers excel at generalizing shared structure (within-task rule generalization, cross-task transfer) but perform worse on memorizing unique features (summer locations, temporal stimulus onset); splitters show the opposite profile.
- Implications: Humans and ANNs face analogous computational constraints during continual learning—balancing knowledge transfer against memory protection. This trade-off depends on both external factors (task similarity) and internal strategies (representational overlap versus separation), suggesting shared principles of generalization and interference across biological and artificial learning systems.
Hippocampus supports multi-task reinforcement learning under partial observability
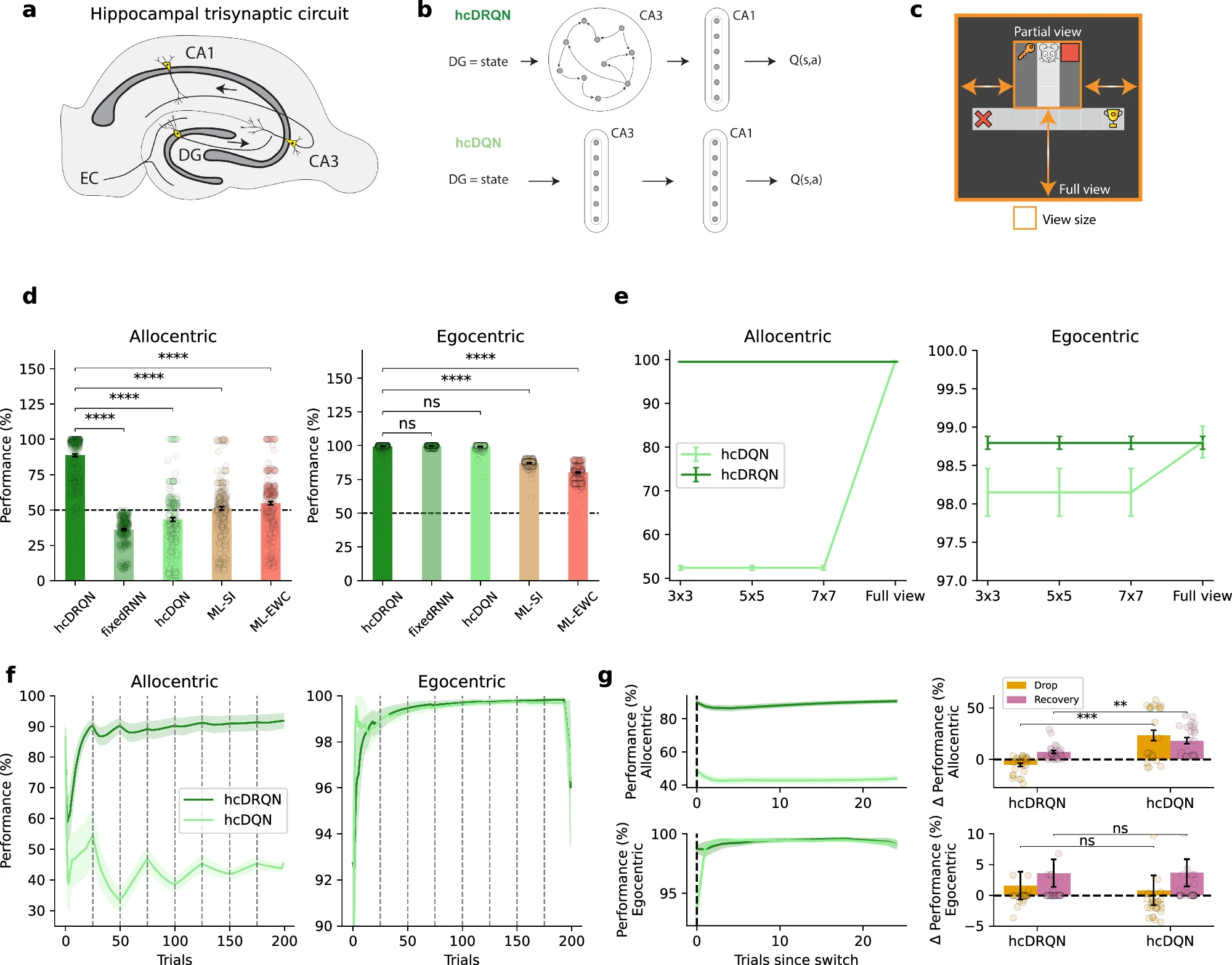
- Main contribution: Demonstrates that hippocampal recurrence (e.g., CA3) is essential for goal-directed navigation in partially observable environments by training deep RL agents (hcDRQN) on ego- and allocentric T-maze tasks and comparing them to animal behavior and neural recordings.
- Key insight: Agents with recurrent hippocampal architecture successfully learned both strategies under partial observability (matching animal performance), while feedforward networks (hcDQN) failed—even with continual learning algorithms. Recurrence enables temporal integration of sparse sensory cues for decision-making at later choice points.
- Experimental validation: Using demixed PCA on CA1 recordings, the recurrent model better captured strategy-specific, temporal, and decision-related neural dynamics. Recurrent agents also matched animal trajectories, state-occupancy patterns, and spatial coding properties (place fields, spatial information) more closely than feedforward alternatives.
- Predictions: The model predicts that (1) hippocampal recurrence supports robust generalization to novel maze lengths, stochastic cue removal, and sensory noise; (2) agents trained under full observability fail to replicate experimental data, suggesting partial observability better reflects naturalistic conditions; (3) recurrent plasticity is necessary for multi-task learning and adaptation.
References
- 1
- 2
- 3
- 4
- 5